I'm begining a new Elixir Phoenix project and decided to try out version 1.3 after watching Chris McCord's talk on it, and since I'm already using Bootstrap 4 + Font Awesome at work in a Rails project it makes sense to continue using them here.
I searched around a bit for the best way to include Bootstrap 4 and Font Awesome but couldn't find anything that worked 100% correctly for me, esp with regards to Font Awesome. Bootstrap 4 doesn't ship with Glyphs anymore so it was important to get Font Awesome working.
After a bit of fiddling about I managed to get it all working, this is what I did.
Follow the release note instructions for installing Phoenix v1.3.0-rc.0. There is a rc.1 release available, but no notes.
Create a new Phoenix project, noting we now do mix phx.xxx rather than mix phoenix.xxx.
mix phx.new project_name
Install the needed npm modules, this is from the new assets subfolder in your Phoenix project.
cd project_name/assets
npm install --save-dev sass-brunch copycat-brunch
npm install --save bootstrap@4.0.0-alpha.6 font-awesome jquery
cd ..
Update the Brunch config now located in assets/brunch-config.js to use the installed modules.
Add two entries to the plugins section for copying the fonts and sass paths:
copycat:{"fonts":["node_modules/font-awesome/fonts"]// copy node_modules/font-awesome/fonts/* to priv/static/fonts/},sass:{options:{includePaths:["node_modules/bootstrap/scss","node_modules/font-awesome/scss"],// tell sass-brunch where to look for files to @importprecision:8// minimum precision required by bootstrap}}
And finally make it all available in the npm section:
globals:{// Bootstrap JavaScript requires both '$', 'jQuery', and Tether in global scope$:'jquery',jQuery:'jquery',Tether:'tether',bootstrap:'bootstrap'// require Bootstrap JavaScript globally too}
OR here goes the complete file to copy if you're still using the default:
exports.config={// See http://brunch.io/#documentation for docs.files:{javascripts:{joinTo:"js/app.js"// To use a separate vendor.js bundle, specify two files path// https://github.com/brunch/brunch/blob/master/docs/config.md#files// joinTo: {// "js/app.js": /^(js)/,// "js/vendor.js": /^(vendor)|(deps)/// }//// To change the order of concatenation of files, explicitly mention here// https://github.com/brunch/brunch/tree/master/docs#concatenation// order: {// before: [// "vendor/js/jquery-2.1.1.js",// "vendor/js/bootstrap.min.js"// ]// }},stylesheets:{joinTo:"css/app.css",order:{after:["priv/static/css/app.scss"]// concat app.css last}},templates:{joinTo:"js/app.js"}},conventions:{// This option sets where we should place non-css and non-js assets in.// By default, we set this to "/assets/static". Files in this directory// will be copied to `paths.public`, which is "priv/static" by default.assets:/^(static)/},// Phoenix paths configurationpaths:{// Dependencies and current project directories to watchwatched:["static","css","js","vendor"],// Where to compile files topublic:"../priv/static"},// Configure your pluginsplugins:{babel:{// Do not use ES6 compiler in vendor codeignore:[/vendor/]},copycat:{"fonts":["node_modules/font-awesome/fonts"]// copy node_modules/font-awesome/fonts/* to priv/static/fonts/},sass:{options:{includePaths:["node_modules/bootstrap/scss","node_modules/font-awesome/scss"],// tell sass-brunch where to look for files to @importprecision:8// minimum precision required by bootstrap}}},modules:{autoRequire:{"js/app.js":["js/app"]}},npm:{enabled:true,globals:{// Bootstrap JavaScript requires both '$', 'jQuery', and Tether in global scope$:'jquery',jQuery:'jquery',Tether:'tether',bootstrap:'bootstrap'// require Bootstrap JavaScript globally too}}};
Next, rename assets/css/app.css to assets/css/app.scss and create a place for custom styles.
And lastly don't forget to delete the included Phoenix css which contains Bootstrap 3 and it's custom styles.
rm assets/css/phoenix.css
The default Phoenix app welcome page looks pretty broken now, but that's good as it means it's using Bootstrap 4. My next step was to swapped it out for one of the examples.
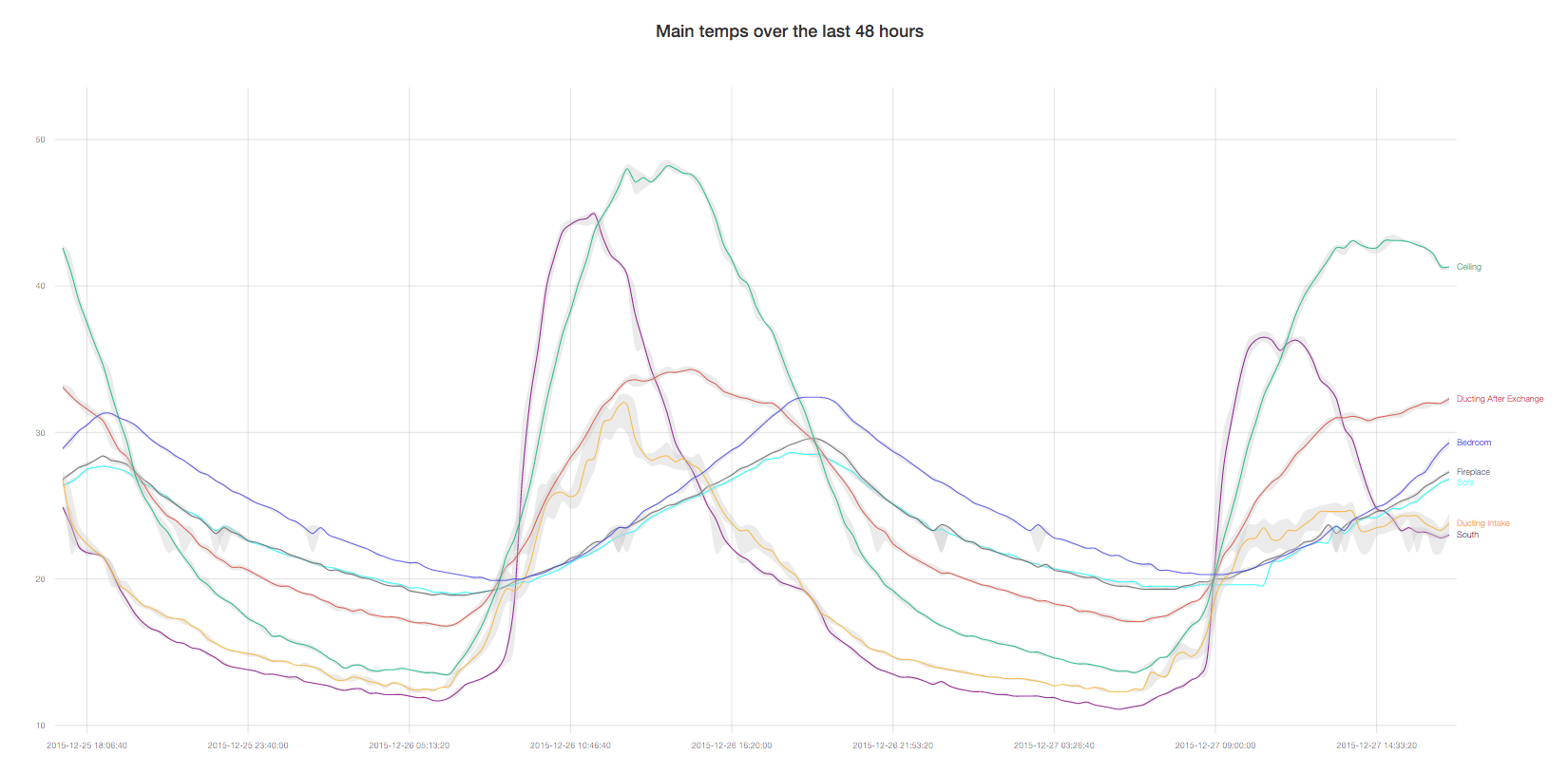
I'm at the begining stages of converting a Rails IoT project to Phoenix. Initially I plan to replicate my temperature dashboard, which has the below graph on it.
The green line is the air temperature in my ceiling space, I have a metal roof which is why it heats up to over 50C on some days. Something needs to be done about the heat as it has a massive flow on effect throughout the house in summer. That's another post though.
So far I've created a blank Phoenix app and begun to setup a few models to represent my existing Rails tables so that I can pull the data which powers the dashboard. I immediately encountered an issue as I'm using UUID primay keys everywhere.
As far as I'm aware there is no standard way to default the primary key to being :uuid in Rails, and as a result I'd sometimes forget. The same seems to be the case for Ecto migrations too.
If you get the following error when running the above migration with mix ecto.migrate
ERROR (undefined_function): function uuid_generate_v4() does not exist
Then you need to add the UUID extension to your database from psql like this:
CREATE EXTENSION IF NOT EXISTS "uuid-ossp" WITH SCHEMA public;
Or you can create an extension to do it for you, just make sure your Postgres user has the appropriate rights, and that this migration runs first.
defmoduleMyApp.Repo.Migrations.AddUuidExtensiondouseEcto.Migrationdefupdoexecute"CREATE EXTENSION IF NOT EXISTS \"uuid-ossp\" WITH SCHEMA public;"enddefdowndoexecute"DROP EXTENSION \"uuid-ossp\";"endend
To then get Ecto in Phoenix using database generated UUIDs isn't straight forward as it doesn't support this, only client side generation is. After a bit of research I've found you can get database generated primary keys used, but it's a bit of a hack.
Reading the Ecto.Schema docs shows how straight forward is it to switch the default primary and foreign key types to :uuid. The problem is that this line in MyApp.Web.Model will cause Ecto to generate the primary_key client side and send that in the insert statements:
@primary_key{:id,:binary_id,autogenerate:true}
If I then run Repo.insert %Reading{} from iex -S mix I get the following debug output, note the sql generated includes the UUID being set.
In particular it's the autogenerate option causing this, if this was of type :id instead of :binary_id Ecto would let the database generate the ID. You can see that stated in the code Ecto is generating the UUID. So what to do about this, you can remove the autogenerate: true, but that doesn't stop Ecto sending the id field, it's just now nil which causes a constraint error:
The trick is to use before_insert from Ecto.Model.CallBacks to remove the :id field from the changeset before the query statement is generated. MyApp.Web.Model can be updated like this:
The read_after_writes option will not trigger a select but simply means the database generated id is read from the return response. Now when I insert a new record the :id field is not being set, a RETURNING statement is included and the returned model has a primary key.
The convention is to let the client generate the UUID as by their very nature it will be unique, but at this stage I'm going to stick with how the system I'm replacing works. It's not a great idea to immediately go against convention when learning something new, but this hack is quite self contained, and I sure did learn heaps trying to figure all this out.
I have been doing full time dev in Rails for almost 10 years now and the itch to give something else a serious play has been getting stronger and stronger of late. As a backend focused developer I seem to constantly battle heavy loads, trying to push them off the request and into the background, so the parallelism and distributed aspects of Elixir appeal to me. Not to mention it’s speed compared to Ruby.
Over the last couple of years I’ve developed a sizeable IoT setup at home with over 100 sensors involving RaspberryPI, BeagleBone Black and Mac hardware collecting and processing all of the data flooding in. Running on this is a mixture of Rails and NodeJS with RabbitMQ at the core. Over the last few months I’ve stopped development of it as I plan to switch over to Elixir and Phoenix as that seems like a much better fit for where I want to take my system - The Homeatron9000.
So far I’ve read most of the elixir-lang.org Getting Started section, the first ~100 pages of Programming Elixir, and have recently reached the Testing chapter in Programming Phoenix. It’s only now that I’m starting to try my own hand at some code, first up I’m jumping straight into replacing my main Rails app. As I do this I’ll be talking here about the move from a Rails developer`s point of view, the good, the bad, the ugly and hopefully the pretty.
Recently I was trying to solve a problem where it would have been quite handy to show if users were actively accessing the site from multiple browser tabs at the same time. So after a bit of thinking and hacking I came up with the following solution.
I now have a small Javascript snippet that given a unique id for a browser tab, inserts it as a hidden field into all FORMs and adds it to the data POSTed with all AJAX requests. This means that I’m not identifying where GETs come from, but that’s fine for my situation as GETs don’t change data. On the server side I’m then extracting this field and including it as a tag in my log against each request along with user and session identifiers. I can then filter my logs by the session and then see if there are interleaved requests with more than one browser tab ID.
That’s all pretty straight forward, obviously the tricky part is identifying the browser tab. I’m doing this by using the sessionStorage API where “Opening a page in a new tab or window will cause a new session to be initiated”, or in fact simply changing domains in a tab appears to reset the session too.
So the flow is like this: once the page loads the Javascript snippet checks the session storage for a previously stored browser tab identifier and uses that, if it’s not there it stores a newly generated one which is then used. I don’t really trust Javascript GUIDs to be unique, so I’m generating them server side and including them in a META tag.